
Numerai
In this tutorial we will use Snowflake and its Python integration, Snowpark, to participate in the Numerai tournament. Numerai is a data-driven hedge fund that runs a forecasting competition. Data scientists compete to build the best predictive models using obfuscated financial data provided by Numerai. The models are ranked based on their future performance.
Snowflake
Snowflake, on the other hand, is a cloud-based data warehousing platform that allows one to store, manage, and process data. One of Snowflake’s features, Snowpark, provides Python integration which allows one to execute code directly on the Snowflake cloud. This enables the use of Snowflake’s scalable and flexible infrastructure, which can mitigate hardware constraints when training and deploying models.
The RAM problem
The large size of the Numerai dataset presents a challenge, as RAM can quickly become an issue, especially when using pandas. Training a model on Snowflake can mitigate this, although if your model requires a GPU you will still need a separate service.
Step 1
Create a Snowflake account.
Download the data from Numerai to a local folder.
Create the required objects in Snowflake.
use role sysadmin;
-- replace with your database name
use lukas;
-- replace with your schema name
use schema public;
CREATE OR REPLACE WAREHOUSE snowpark_opt_wh WITH
WAREHOUSE_SIZE = 'MEDIUM'
WAREHOUSE_TYPE = 'SNOWPARK-OPTIMIZED'
MAX_CLUSTER_COUNT = 10
MIN_CLUSTER_COUNT = 1
SCALING_POLICY = STANDARD
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE
INITIALLY_SUSPENDED = TRUE
COMMENT = 'created by lukas for machine learning';
create or replace file format numerai_parquet
TYPE = PARQUET
COMPRESSION = SNAPPY;
create or replace file format numerai_json
type = json
compression = auto;
-- create external stages
create or replace stage numerai_stage
file_format = numerai_parquet;
create or replace stage numerai_json_stage
file_format = numerai_json;
create stage numerai_models;
Step 2 – upload the data
Do the following in snowsql to upload the files to Snowflake. Upload the json data to the json stage and the parquet files to the numerai stage. Keep in mind it can take a while
put 'file:///Users/path_to_downloaded_data/train.parquet' @numerai_stageStep 3 – move the files into a table
Now that you have uploaded the files, you need to copy them into a table. You can run the following in a worksheet. Make sure to run it twice, once for the train and once for the validation data.
import snowflake.snowpark as snowpark
# change the location to do both validation and train data
table_name = 'NUMERAI'
location = '@numerai_stage/validation.parquet'
def main(session):
session.sql('use role sysadmin').collect()
session.use_schema('PUBLIC')
df = session.read.option("compression", "snappy").parquet(location)
df.copy_into_table("{}".format(table_name))
return 'success'Step 4 – create view from json data
The json file contains the names of the columns of the data. we need to convert it into an easily queryable table in snowflake.
create or replace view numerai_targets as
select VALUE as target_list
from @numerai_json_stage/features.json,
LATERAL FLATTEN( INPUT => $1:targets );
select * from numerai_targets;
create or replace view numerai_features_medium as
select value as feature
from @numerai_json_stage/features.json,
LATERAL FLATTEN( INPUT => $1:feature_sets.medium );
create or replace view numerai_features_small as
select value as feature
from @numerai_json_stage/features.json,
LATERAL FLATTEN( INPUT => $1:feature_sets.small );Step 5 – train your model
Now that everything is set up, we can start training our model. For this tutorial we will make a simple model using the parameters supplied by Numerai in their example script. The full_df function gets the training data from the table. The second function trains the model and saves it to a stage. Make sure to use the snowpark optimized warehouse we created earlier.
import snowflake.snowpark as snowpark
from snowflake.snowpark.functions import col
from lightgbm import LGBMRegressor
from joblib import dump
def full_df(session):
features = session.table("NUMERAI_FEATURES_MEDIUM")
features = features.to_local_iterator()
feature_list = [f[0] for f in features]
feature_list = ['"target_nomi_v4_20"'] + feature_list
data = session.table('numerai').select(feature_list).filter(col('"data_type"') == 'train')
return data.to_pandas()
def makemodel(session):
data = full_df(session)
y = data[["target_nomi_v4_20"]]
features = session.table("NUMERAI_FEATURES_MEDIUM")
features = features.to_local_iterator()
feature_list = [f[0].strip('\"') for f in features]
x = data[feature_list]
params = {"n_estimators": 2000,
"learning_rate": 0.01,
"max_depth": 5,
"num_leaves": 2 ** 5,
"colsample_bytree": 0.1}
model = LGBMRegressor(**params)
print('fitting model ...')
model.fit(x,y)
print('done ...')
dump(model, '/tmp/model2')
upload = session.file.put('/tmp/model2', '@NUMERAI_MODELS', auto_compress=False, overwrite=True)
return upload[0].status
def main(session):
status = makemodel(session)
return statusStep 6 – predict
Now we can test our model on the validation data.
import snowflake.snowpark as snowpark
from snowflake.snowpark.functions import col
from joblib import dump, load
from lightgbm import LGBMRegressor
#feature_set,modelname = "NUMERAI_FEATURES_SMALL",'model1'
feature_set,modelname = "NUMERAI_FEATURES_MEDIUM",'model2'
def full_df(session):
features = session.table(feature_set)
features = features.to_local_iterator()
features = [f[0] for f in features]
cols = ['"id"', '"target_nomi_v4_20"'] + features
data = session.table('numerai').select(cols).filter(col('"data_type"') == 'validation').to_pandas()
return data
def predict(session):
data = full_df(session)
y = data[["id","target_nomi_v4_20"]]
x = data.drop(columns=["id","target_nomi_v4_20"])
del data
session.file.get(f"@NUMERAI_MODELS/{modelname}", '/tmp/' )
with open(f'/tmp/{modelname}', "rb") as f:
model = load(f)
prediction = model.predict(x)
y['prediction'] = prediction
diagnostic = y[["target_nomi_v4_20", "prediction"]]
corr = diagnostic.corr(method="spearman")
print('spearman',corr)
corr = diagnostic.corr(method="pearson")
print('pearson',corr)
return session.create_dataframe(y[['id','prediction']])
Evaluation
We can download the predictions as a csv directly from the web interface. Under the output tab we can see the correlation between our model and the targets. I created 2 models, one using the small feature set and the other using the medium. The medium appears to perform slightly better.


After you have downloaded the results you can upload them to Numerai to get a more complete analysis of your model.
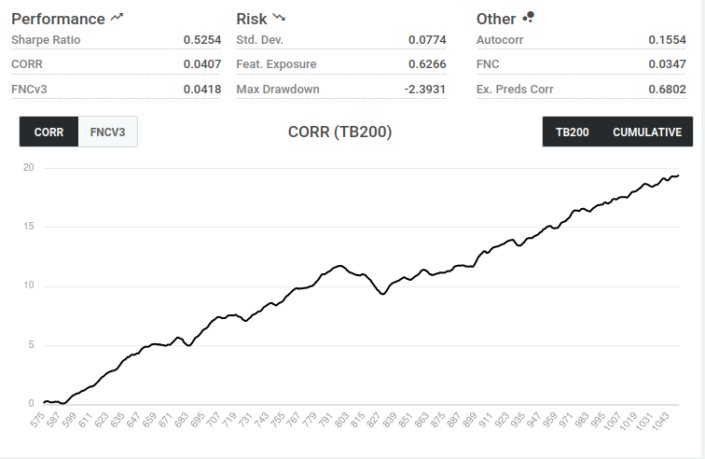
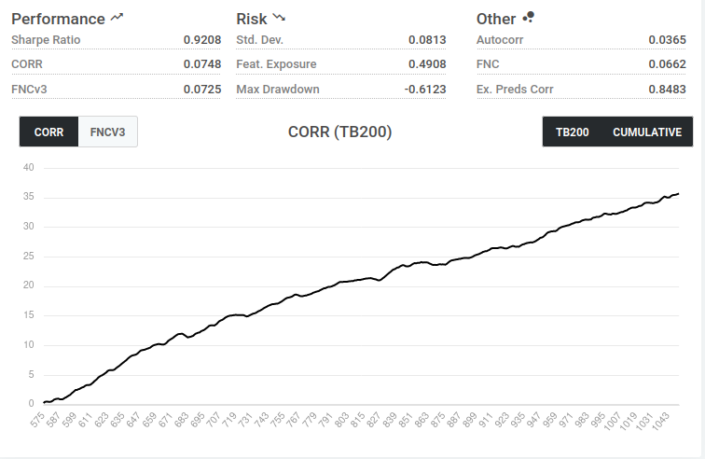
You can also download the models from Numerai to run elsewhere;
get @NUMERAI_MODELS "file:///Users/path_to_download_location/";Summary
Snowflake’s python integration allows you to run python code directly on your data. This can alleviate some of the performance issues of creating models locally. If you are interested in a brief overview of running python on Snowflake, check out my other blog; Machine Learning in Snowflake. For more about the Numerai tournament check out their website.