
Data Preparation using Builder: removing duplicates
When starting with a new dataset in Tableau one of the first actions should be deduplicate in Prep. Deduplication is part of the first Normal Form to remove redundancy. For this example I have created a small dummy dataset inspired by Kaggle data set containing all F1 Races between 1955 and 2022.
The dummy data set
The dummy data set to illustrate the two methods is kept simple.
| raceId | season | name | date |
| 1051 | 2021 | Qatar Grand Prix | 21/11/2021 |
| 1052 | 2021 | Bahrain Grand Prix | 28/3/2021 |
| 1052 | 2021 | Bahrain Grand Prix | 28/3/2021 |
| 1053 | 2021 | Emilia Romagna Grand Prix | 18/4/2021 |
| 1054 | 2021 | Portuguese Grand Prix | 2/5/2021 |
| 1055 | 2021 | Spanish Grand Prix | 9/5/2021 |
| 1056 | 2021 | Monaco Grand Prix | 23/5/2021 |
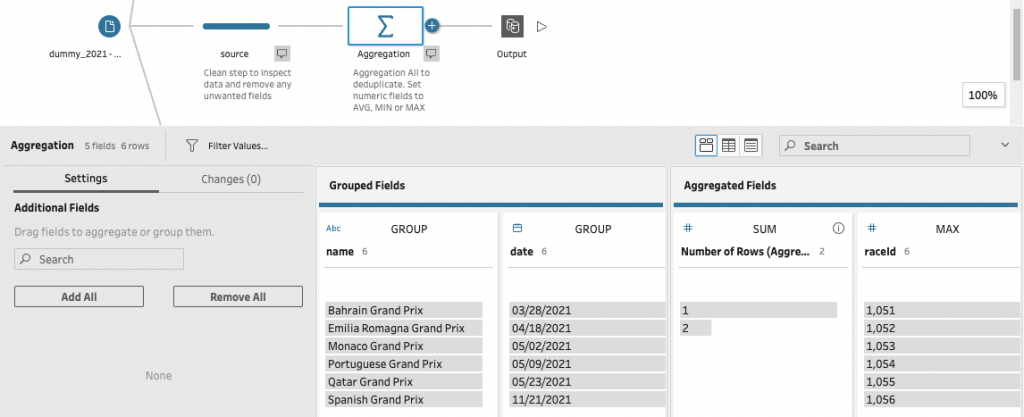
Method 1 – Deduplication with Aggregate
Within Prep the classic method uses Aggregate to deduplicate.
After the data file create an Aggregate step, or as in below flow example a Clean step can created first to inspect and remove any unwanted fields.
Note that while using that method you ensure numeric Fields like round, year are aggregated as average, maximum or minimum. I have used MAX.
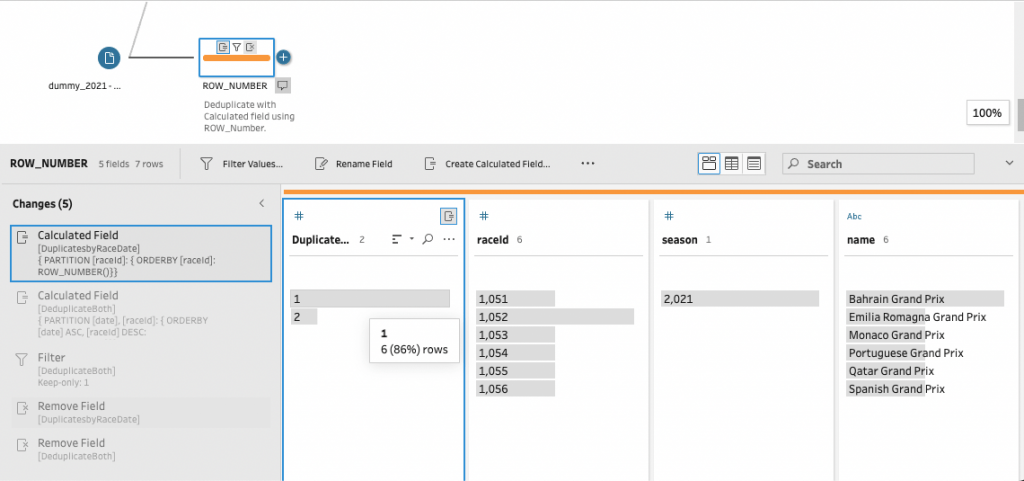
Method 2 – an alternative to deduplication with ROW_NUMBER
Another way to deduplicate is with the function ROW_NUMBER. First create a Clean step, and then Create a Calculated Field using a custom calculation.
ROW_NUMBER can be used to check for duplicates:
{ PARTITION [raceId]: { ORDERBY[raceId]:ROW_NUMBER() }} // a single field deduplication.The ROW_NUMBER function in the code above assigns a sequential row ID to each unique row. ORDERBY sequences the rows by the selected field. PARTITION will then return the number of duplicate rows by the selected Field. In effect it Groups each value of the Field.
Note that ORDERBY can have multiple fields and can be changed to ascending by adding the ASC expression behind the field. Assess if a single or multiple calculation is needed on your data set. In this dataset the following can be done:
{ PARTITION [date], [raceId]: {ORDERBY [date], [raceId] ASC: ROW_NUMBER() } }The flow would be one clean step with one ROW_number calculation. In below image I have added both options.
Deduplicated Data set
When you would use either method in your flow with periodic data refresh, and expect possible duplicates to occur, then add a step to remove duplicates. Remove duplicates by adding a Filter change in your existing Clean step. An easy way to do this is in the Profile Pane of the deduplication step and licking on number 1, selecting Keep Only.
Note that in Alteryx you can use the Unique Tool, you can read more about it in this blog post.
I hope this small guide on deduplication was helpful. Check my blogs for more Tableau and Tableau Prep content.
Which option would you use?
If you want to read other blogs about software like Tableau and Alteryx, follow a training course or book a consultant please visit The Information Lab NL for more information.