
The Tokenize is one of the four output methods of the Regular Expression tool. Thanks to this method you can specify a regular expression that will be parsed into separate columns. It can be the entire expression or a marked group and only that will be parsed.
It looks like the ‘Text To Column’ tool but Tokenize is much more powerful because you decide what you want to split!
In this set below, I want to parse the words between the dots in 3 columns.
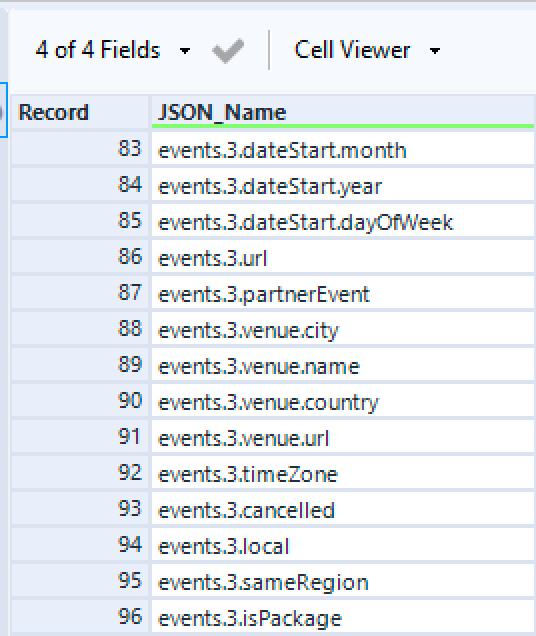
If I use the ‘Text to Column’ tool with the dot as a delimiter, I will have this
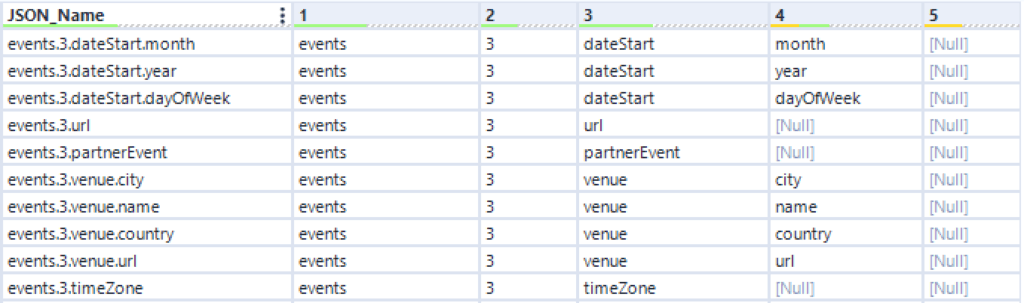
I have a column that I don’t need with the digits.
Let’s see what would be the difference by using the Tokenize option within the ‘RegEx’ tool.
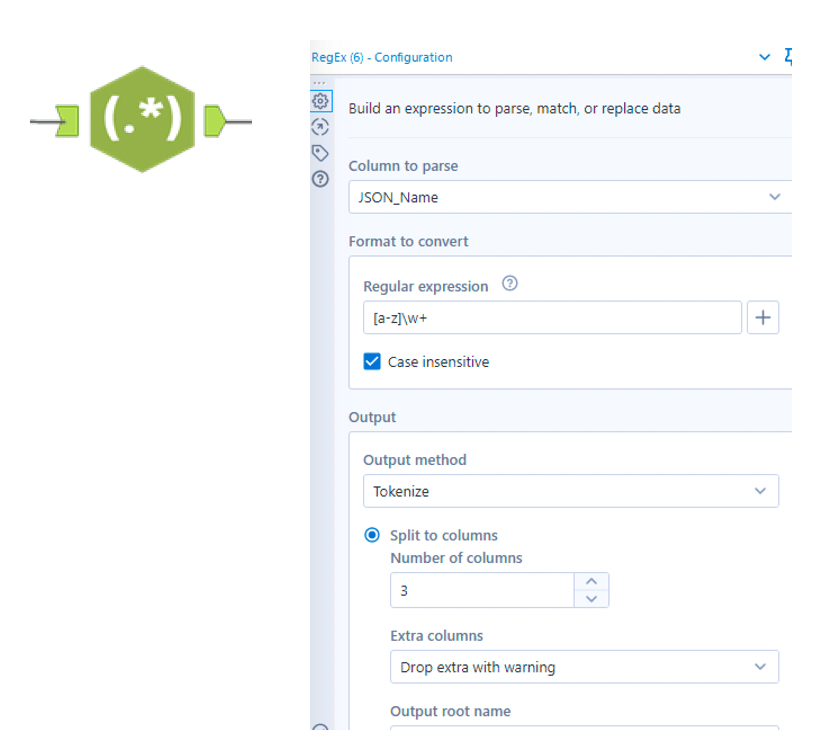
I use this RegEx expression [a-z]\w+ that will take all single character that match any word character (\w+), so it won’t capture the points and the digits.
I choose ‘Tokenize’ for the Output method and set to 3 the number of columns.
Here is the result, so exactly the 3 columns that I need
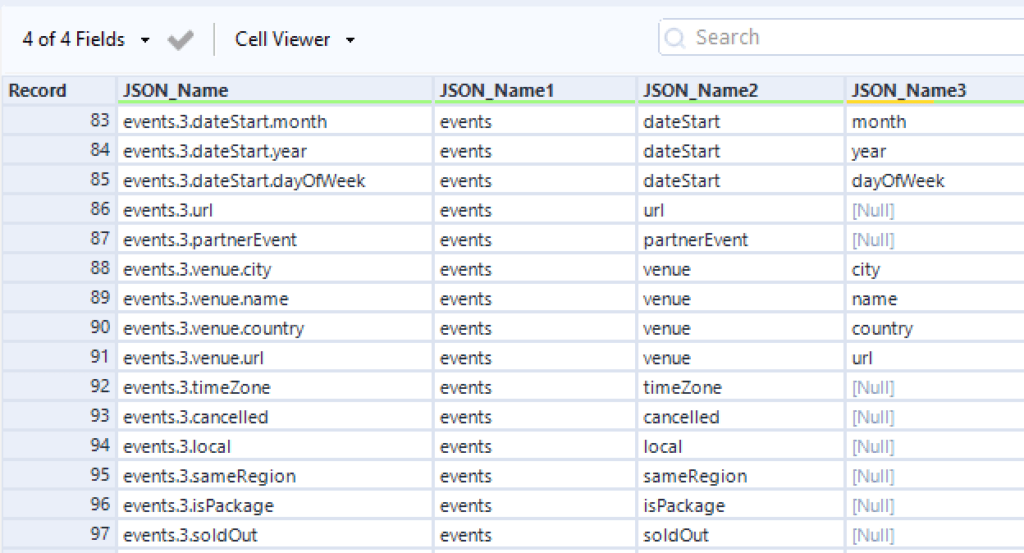
Be aware that with the Tokenize method you can only use one market group.
I highly recommend this website with this website https://regex101.com to learn and test RegEx!
You will find more info about Regex in this blogpost Using Regex to find key information from a free input text field – The Data School