
dbt (tool voor het bouwen van gegevens) stelt analytics-engineers in staat om gegevens in hun datawarehouses te transformeren door simpelweg SQL select-statements te schrijven. dbt zorgt ervoor dat deze select-statements worden omgezet in tabellen en views.
dbt doet de T in ELT-processen (Extract, Load, Transform) – het extract of laadt geen gegevens, maar het gaat bovenop de database zitten en werkt hier als een schil omheen. Het is buitengewoon goed in het transformeren van gegevens die al in je warehouse zijn geladen. Dit zorgt er dus voor dat er je geen tijd kwijt bent aan het onttrekken en opnieuw uploaden van data vanuit en richting je warehouse.
Hoe gebruik je dbt?
dbt maakt verbinding met je datawarehouse om query’s voor gegevenstransformatie uit te voeren. Als zodanig heb je een datawarehouse nodig met daarin geladen brongegevens om dbt te gebruiken. dbt ondersteunt native verbindingen met Snowflake, BigQuery, Redshift en Postgres datawarehouses, en er zijn een aantal door de gemeenschap ondersteunde adapters voor andere magazijnen.
Nadat er verbinding is gemaakt met de database, wordt er gevraagd met welk git systeem je wilt gaan werken om 1 van de krachten van dbt mogelijk te maken ; versiebeheer.
Na deze eerste stappen, wordt je geconfronteerd met een niet veel zeggende mappen structuur :
Maar deze mappen structuur geeft aan hoe dbt werkt en is in de basis niet meer als een verzameling .sql en .yml bestanden. De .sql bestanden gaan de select statements bevatten waarmee je de views of tabellen wilt bouwen , de .yml bestanden geven je de mogelijkheid om dbt verder aan te sturen.
Voordelen van het gebruik van dbt
versiebeheer : git
We hebben het al even laten doorschemeren maar 1 van de voordelen van dbt is de integratie van git. Dit zorgt voor de mogelijkheid tot versiebeheer en het eenvoudig afsplitsen en samenbrengen van de code achter je datawarehouse. Waar voorheen altijd uitgebreide documentatie en backups nodig waren , zorgt git ervoor dat dit allemaal overzichtelijk gebeurt en er ten alle tijden kan worden terug gevallen op een oudere versie.
Automatische testing
Zeker zijn van accurate en huidige data is altijd een groot goed maar niet altijd vanzelf sprekend. Om dit te waarborgen stelt dbt je in staat om je data te testen voordat het verder in de database wordt verwerkt. Denk hierbij niet alleen maar aan de (ingebouwde!) constraint-tests of nagaan of een column geen null-waarde bevat maar ook tests die je zelf kunt schrijven ; vallen alle waarden in een column wel binnen een verwachte range ? Op deze manier kun je de Analytics Engineer in staat stellen om fout aannames of data te signaleren voordat de business er zelf last van ondervindt.
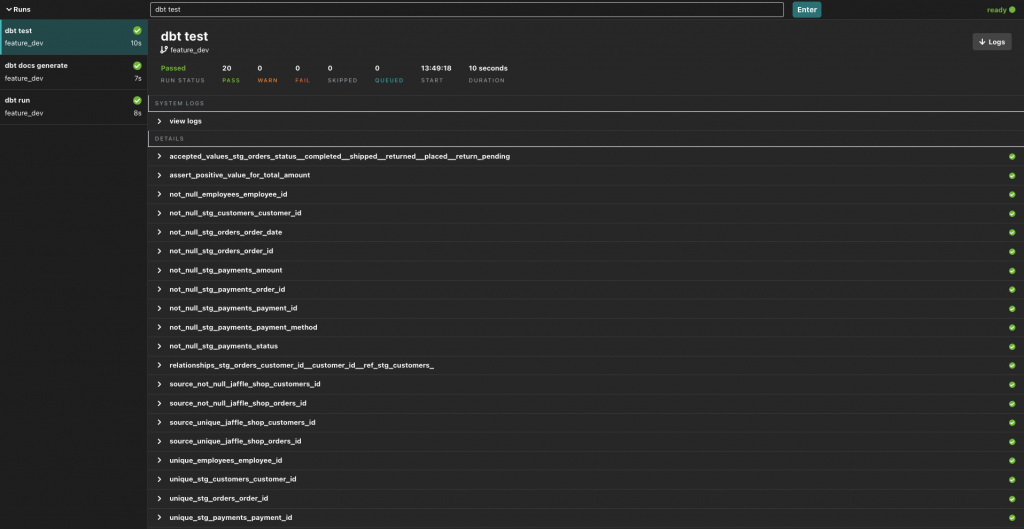
Naast het testen op fouten , kan er ook worden gekeken naar de “versheid” van de data ; wanneer is deze voor het laatst veranderd? Hiermee kunnen mogelijke issues met pipelines worden opgespoord voordat de business aan de slag gaat met verouderde data.
Inzicht in afkomst
dbt stelt je ook in staat om snel inzicht te krijgen in de bronnen van je data en tabellen. In het Lineage overzicht zie je snel hoe alle data met elkaar samenhangt en waar de verschillende afhankelijkheden zitten:
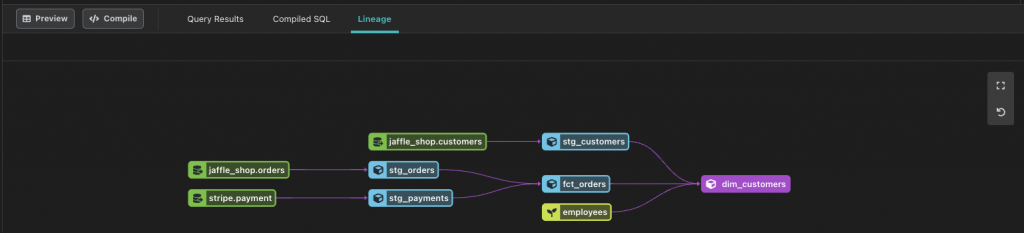
Bouw volgorde
Met behulp van de eerder genoemde lineage, kan dbt ook makkelijker bepalen in welke volgorde de verschillende tabellen moeten worden opgebouwd. In het bovenstaande voorbeeld is het niet heel nuttig om dim_customers op te bouwen voordat stg_customers en fct_orders compleet zijn.
Dit gebeurt allemaal automatisch en hoeft niet handmatig te worden ingesteld door de analytics engineer.
Documentatie
Iedereen weet hoe belangrijk accurate en uitgebreide documentatie is maar niemand heeft ooit zin (of tijd) in het maken hiervan. dbt komt daarom met een uitgebreide documentatie functie die alle tabellen en views in detail beschrijft:
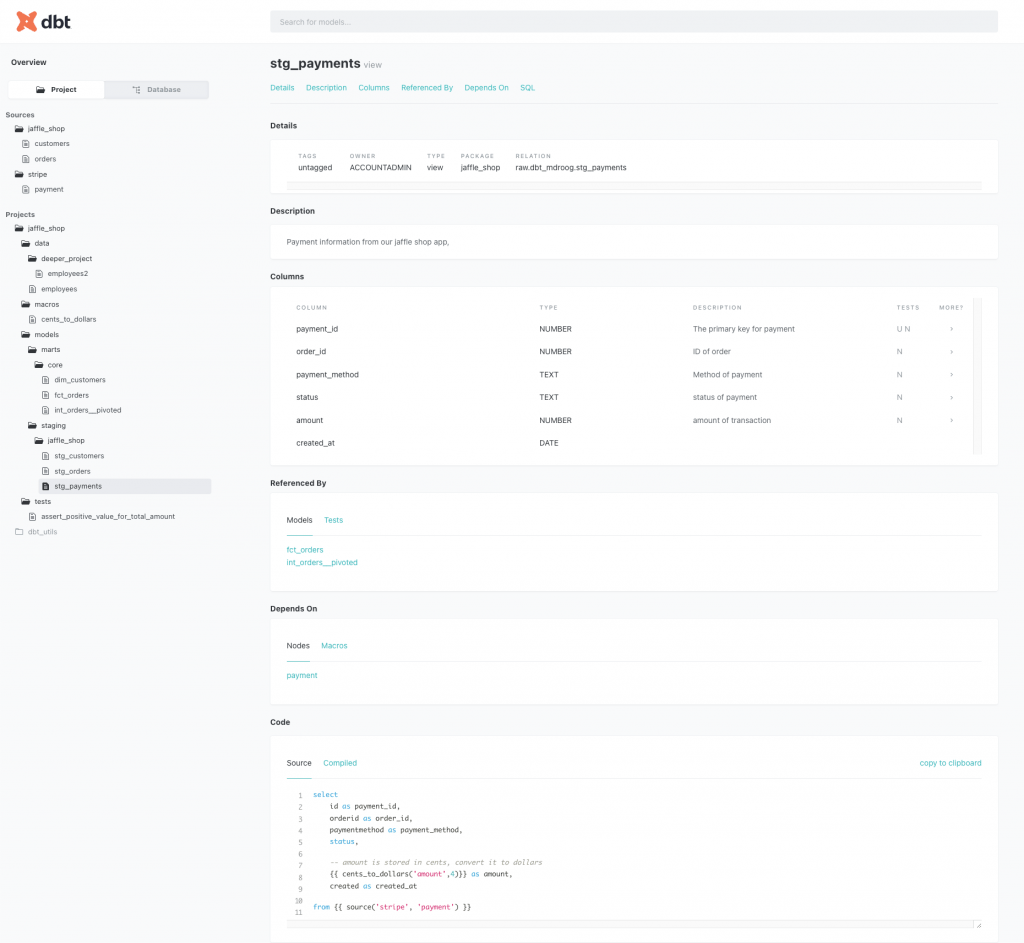
Deze documentatie geeft een snel en helder overzicht over elke tabel en view. Hierin wordt een waslijst aan data meegenomen :
– database detail informatie
– omschrijvingingen die zijn meegegeven door de engineer
– kolom informatie met datatype en toegepaste testing
– afhankelijkheden zowel up- als down-stream
– de code behorende bij de tabel/view
Als deze extra mogelijkheden zorgen voor extra grip op je database en proces. Wijzigingen kunnen snel en veilig worden doorgevoerd terwijl je een duidelijk oog op de kwaliteit van je data houdt. Bij The Information Lab zijn we in ieder geval groot fan!