Een Top-N filter kun je gebruiken om de grootste (of kleinste) waarden binnen een dimensie te vinden. Bijvoorbeeld de tien klanten die de hoogste omzet hebben opgeleverd, of de tien gemeenten met het laagste inbraakcijfer. Soms wil je echter meerdere niveaus van dimensies visualiseren. Hoe je met de functie INDEX() het aantal rijen per niveau gelijk kunt houden lees je in de tweede helft van dit blog.
Standaard Top-N
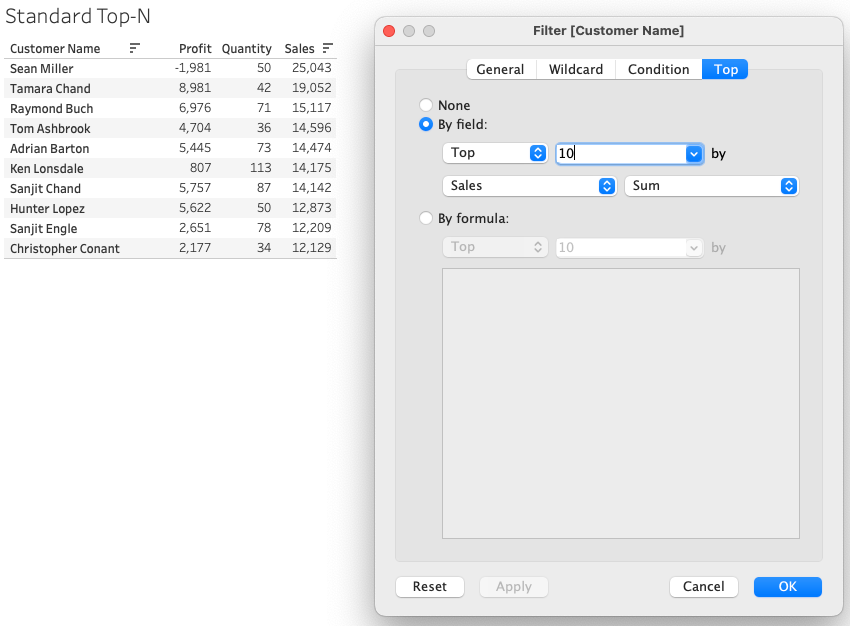
In alle voorbeelden maak ik gebruik van de Sample Superstore dataset. Hieronder zie je de tien klanten gevisualiseerd die verantwoordelijk zijn voor de meeste omzet (Sales) via een standaard Top-N filter.
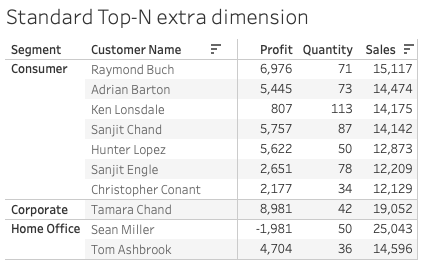
Wanneer je een extra dimensie toevoegt aan de visualisatie zie je nog steeds de tien klanten die de hoogste omzet hebben opgebracht, verdeeld over de nieuwe dimensiewaarden.
Dit zijn de tien klanten die, over de gehele dataset gezien, de hoogste omzet hebben binnen gebracht.
Top-N met gebruik van INDEX()
Maar wat nu als je de top tien klanten wilt zien per segment in plaats van over de gehele dataset? Dan kan je gebruik maken van de functie ‘INDEX()’.
- Als eerste voeg je een calculated field toe met als berekening INDEX().
De naam van het berekende veld doet er verder niet toe, ik kies zelf altijd voor Index. - Vervolgens verwijder je de oude Top-N filter uit de filter shelf.
- Hierna voeg je het nieuwe berekende veld toe aan de filter shelf.
Er verschijnt een pop-up menu waarin je de minimale en maximale waarde van INDEX moet instellen. Stel deze voor nu in op 1 en 10. - Index wordt direct herkend als table calculation. Het is belangrijk dat Index per partitie wordt berekend, dus stel ‘Compute using’ in op ‘Pane (down)’ of ‘Pane (across)’.
Hieronder zie je het resultaat van bovenstaande acties. Voor het overzicht heb ik het berekende veld Index ook toegevoegd aan de tabel.
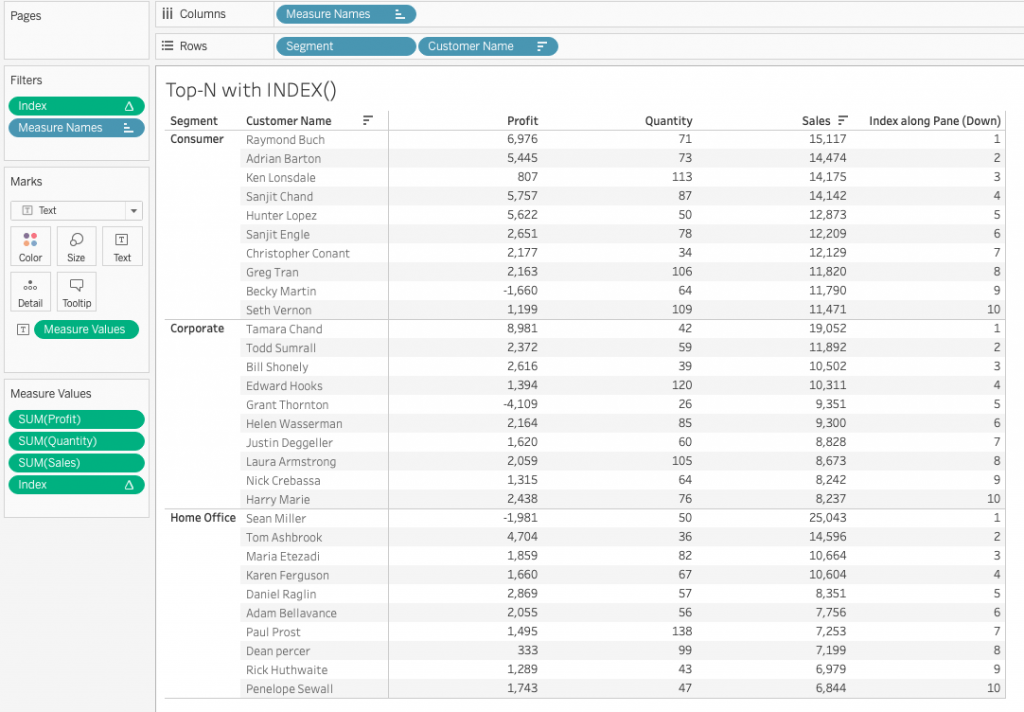
Je kunt zien dat binnen elke partitie (Consumer, Corporate, Home Office) tien rijen worden weergegeven. Ook loopt het nieuwe veld ‘Index along Pane (Down)’ van één tot tien. Dit komt omdat het filter op het berekende veld Index is ingesteld op maximaal tien waarden. Als dit aangepast wordt naar vijf zal elke partitie dus vijf rijen weergeven.
Het voordeel van een Top-N met INDEX() is dat het veld waarover de Top-N ‘berekend’ wordt nu dynamisch is. Het enige wat je hoeft te doen is één van de kolommen te sorteren. Als je bijvoorbeeld de kolom ‘Quantity’ aflopend sorteert zul je binnen elk segment de tien klanten zien die verantwoordelijk zijn voor de hoogste afname in stuks. Sorteer je hetzelfde veld oplopend dan zullen de tien klanten verschijnen die de minste stuks hebben afgenomen.
Heb je meer hulp of uitleg nodig? Aarzel dan niet om contact met ons op te nemen voor onze workshops en trainingen of huur een consultant in.
Wil je nog meer leren over Alteryx of The Information Lab, check dan ons blog of onze website.