Data science, de toekomst voorspellen met data en machine learning waren de hot items in de afgelopen tijd: elk bedrijf zou zijn data moeten gebruiken om de toekomst te voorspellen en er liggen enkel gouden bergen in het verschiet.
Ondertussen weten we dat de gouden berg minder hoog zijn dan dat er wellicht werd voorgespiegeld maar dat het als data tool ontzettend handig kan zijn om in je arsenaal te hebben. Alteryx heeft deze optie ook gezien en heeft daarmee ook de stap gemaakt om de analyse te verheven uit de donkere hoekjes van pure code zoals R en Python, en toegankelijk te maken binnen zijn eigen interface.
Wanneer we dit mededelen aan klanten krijgen we vaak de reactie “Ja , dat is heel mooi, maar hoe dan?!”. Om op deze vraag een antwoord te geven, zullen we de komende periode een aantal blog posts wijden aan dit onderwerp, om als inleiding te dienen voor de koppeling van Predictive Analysis en Alteryx.
De Iris dataset
Iedereen moet ergens beginnen bij het leren van een nieuw onderdeel en dit is hierbij niet veel anders. De aangewezen dataset hiervoor is de Fisher Iris dataset. Deze datase , samengesteld door de Britse statisticus en bioloog Ronald Fisher, is een verzameling van 150 irissen (de bloemen) verdeeld in 3 soorten. Bij elk van deze 150 bloemen zijn 4 gegevens genoteerd:
- Lengte kelkblad
- Breedte kelkblad
- Lengte bloemblad
- Breedte bloemblad
De eerste uitdaging voor onze eerste predictive analyse is om aan de hand van deze 4 gegevens, te voorspellen om welk van de 3 rassen irissen het gaat.
De eerste stap is altijd het las… eigenlijk best gemakkelijk
Het klinkt allemaal heel ingewikkeld maar Alteryx heeft het zo gemaakt dat deze analyse stiekem helemaal zo moeilijk niet is. Allereest een totaal overzicht van de flow:
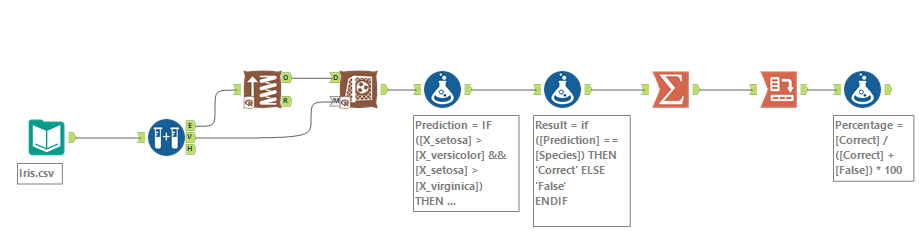
We beginnen , net zoals altijd, met het inladen van onze gegevens d.m.v. een input data tool. De dataset is vrij verkrijgbaar via de UCI database.(https://archive.ics.uci.edu/ml/datasets/iris)
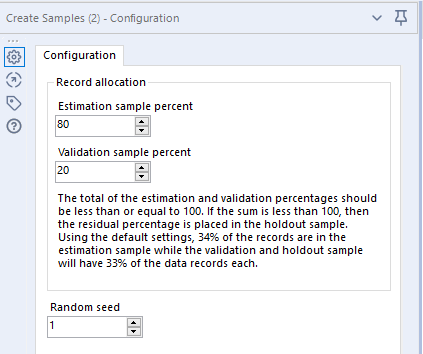
Na het inladen van de data, komen we bij onze eerste analyse stap. We gaan onze dataset van 150 bloemen, opbreken in 2 stukken: een trainingsset en een validatieset. De trainingsset zal worden gebruikt om ons predictive model te trainen en aan de hand van onze validatieset kunnen we vervolgens controlen hoe accuraat dit model is. De tool om dit voor ons te doen is de Create Samples tool die ons vraagt in welke percentages we dit willen verdelen. Een standaard verdeling hiervoor zit tussen de 70/30 en 80/20. In ons voorbeeld heb ik gekozen voor een 80/20 verdeling.
Nu de verdeling is gemaakt, willen we de training van het model starten. Dit doen we door de E(stimation) output van de Create Samples tool, te verbinden aan een Boosted Model tool. De reden voor het gebruik van een Boosted Model tegenover de andere opties zullen we een andere keer behandelen.
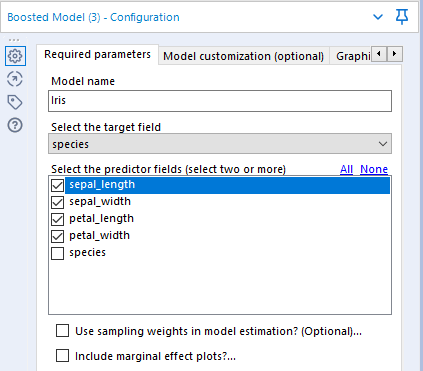
Boosted Model Tool
De Boosted Model tool wil graag 3 dingen van ons weten:
- Wat moet de naam worden van het model?
- Wat moet ik voorspellen?
- Welke gegevens mag ik gebruiken om te voorspellen?
Wanneer we onze regels aan het model hebben doorgeven zijn we qua modelering eigenlijk al bijna klaar. Wat natuurlijk nu belangrijk wordt is achterhalen hoe accuraat ons model is. Dit doen we met een Score tool.
We verbinden ons Boosted Model en de V(alidation) uitgang van de Create Samples tool aan onze Score tool. De functie van deze Score tool is om ons model te gebruiken om te voorspellen om welk ras het gaat. Deze scores woorden in nieuwe kolommen geplaatst en ziet er als volgt uit:

We kunnen in bovenstaande afbeelding zien dat het model heeft bepaald dat bloem 1, 68% kans heeft om een Setosa te zijn, waar bloem 2 al 99% kans heeft.
De score interpreteren
Om deze gegevens vervolgens bruikbaar en overzichtelijk te maken, hebben we 2 formule tools nodig met de volgende codering:
IF([X_setosa] > [X_versicolor] && [X_setosa] > [X_virginica]) THEN 'setosa'
ELSEIF([X_versicolor] > [X_setosa] && [X_versicolor] > [X_virginica]) THEN 'versicolor'
ELSE'virginica'
ENDIF
Hier wordt de scores vergeleken van de kolommen. Het resultaat wordt weggeschreven in een nieuwe kolom die we ‘Prediction’ hebben genoemd.
IF([Prediction] == [Species]) THEN 'Correct' ELSE 'False' ENDIF
Als de kolom voorspelde waarden in Prediction en de (al stiekem bekende waarde) Species gelijk zijn, wordt dit als Correct genoteerd in een nieuwe kolom genaamd ‘Result’.
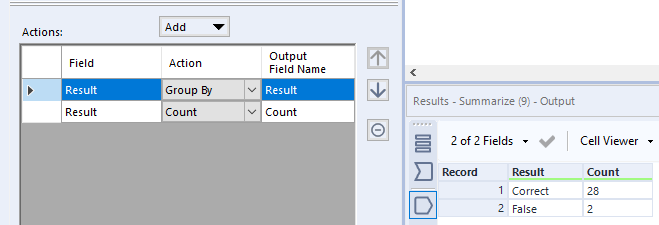
Hierna volgt het optellen van de waarden en een snelle berekening voor het behaalde percentage:
De summarize tool die Result groepeert en vervolgens telt
Een Crosstab tool om de gegevens naast elkaar te plaatsen
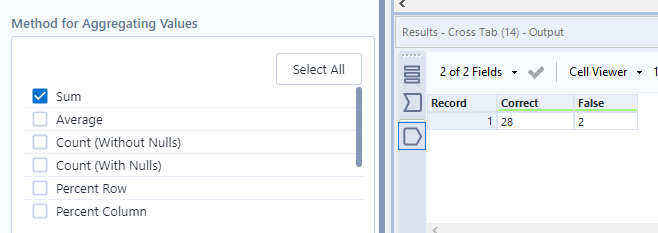
En als laatste een Formula tool die een percentage berekend

Een 93% nauwkeurigheid is een prachtig resultaat voor een eerste model!
Het model opslaan
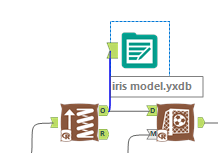
Nu we het model hebben gemaakt, willen we deze natuurlijk ook graag gaan opslaan. We willen ook voorkomen dat onze systemen telkens tijd kwijt zijn aan het opnieuw opbouwen van het model.
Om dit model op te slaan hebben we een kleine extra stap nodig: We verbinden een Output Data tool aan onze Boosted Model tool.
Het model gebruiken
Nu we het model hebben opgeslagen , wordt het tijd om deze te implementeren! Dit doen we als volgt:
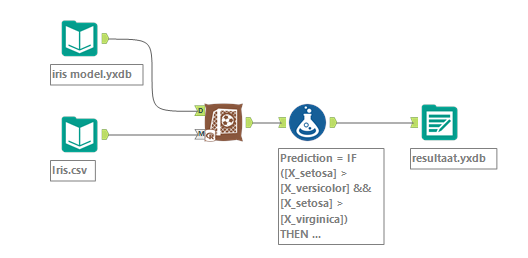
De Boosted Model tool is vervangen door het eerder opgeslagen model en de Create Samples tool is nu ook niet meer nodig en geheel verwijderd.
Waarom zouden we dit nu dan toch verbouwen? We hebben dit model gemaakt met 150 records, dat is een erg laag aantal maar toch kunnen we al duidelijk verschillen zien in de runtime:
Waar het model wordt getraind in 12.7 seconden wordt het gebruikt en toegepast in 4.1 seconden, een derde van de tijd!